Parade Magazine 2005 Earnings Data
Parade2005.RdUS earnings data, as provided in an annual survey of Parade (here from 2005), the Sunday newspaper magazine supplementing the Sunday (or Weekend) edition of many daily newspapers in the USA.
Usage
data("Parade2005")Format
A data frame containing 130 observations on 5 variables.
- earnings
Annual personal earnings.
- age
Age in years.
- gender
Factor indicating gender.
- state
Factor indicating state.
- celebrity
Factor. Is the individual a celebrity?
Details
In addition to the four variables provided by Parade (earnings, age, gender, and state), a fifth variable was introduced, the “celebrity factor” (here actors, athletes, TV personalities, politicians, and CEOs are considered celebrities). The data are quite far from a simple random sample, there being substantial oversampling of celebrities.
Examples
#> Loading required namespace: ineq
## data
data("Parade2005")
attach(Parade2005)
summary(Parade2005)
#> earnings age gender state celebrity
#> Min. : 10000 Min. :18.00 female:62 CA :10 no :119
#> 1st Qu.: 30000 1st Qu.:30.25 male :68 ID : 5 yes: 11
#> Median : 50000 Median :38.50 IN : 5
#> Mean : 1503412 Mean :39.18 VA : 5
#> 3rd Qu.: 78575 3rd Qu.:47.00 FL : 4
#> Max. :42000000 Max. :64.00 IL : 4
#> (Other):97
## bivariate visualizations
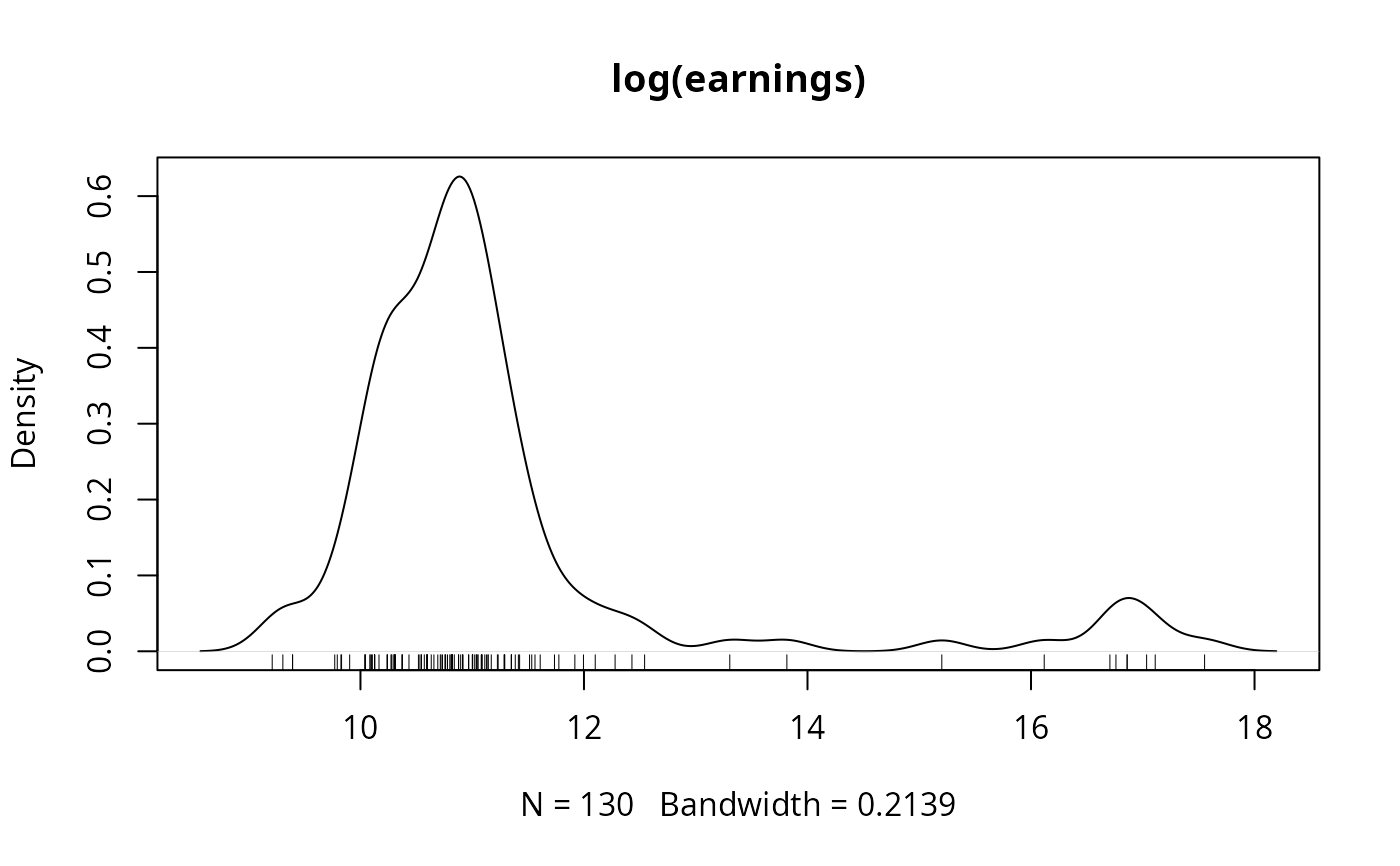
plot(density(log(earnings), bw = "SJ"), type = "l", main = "log(earnings)")
rug(log(earnings))
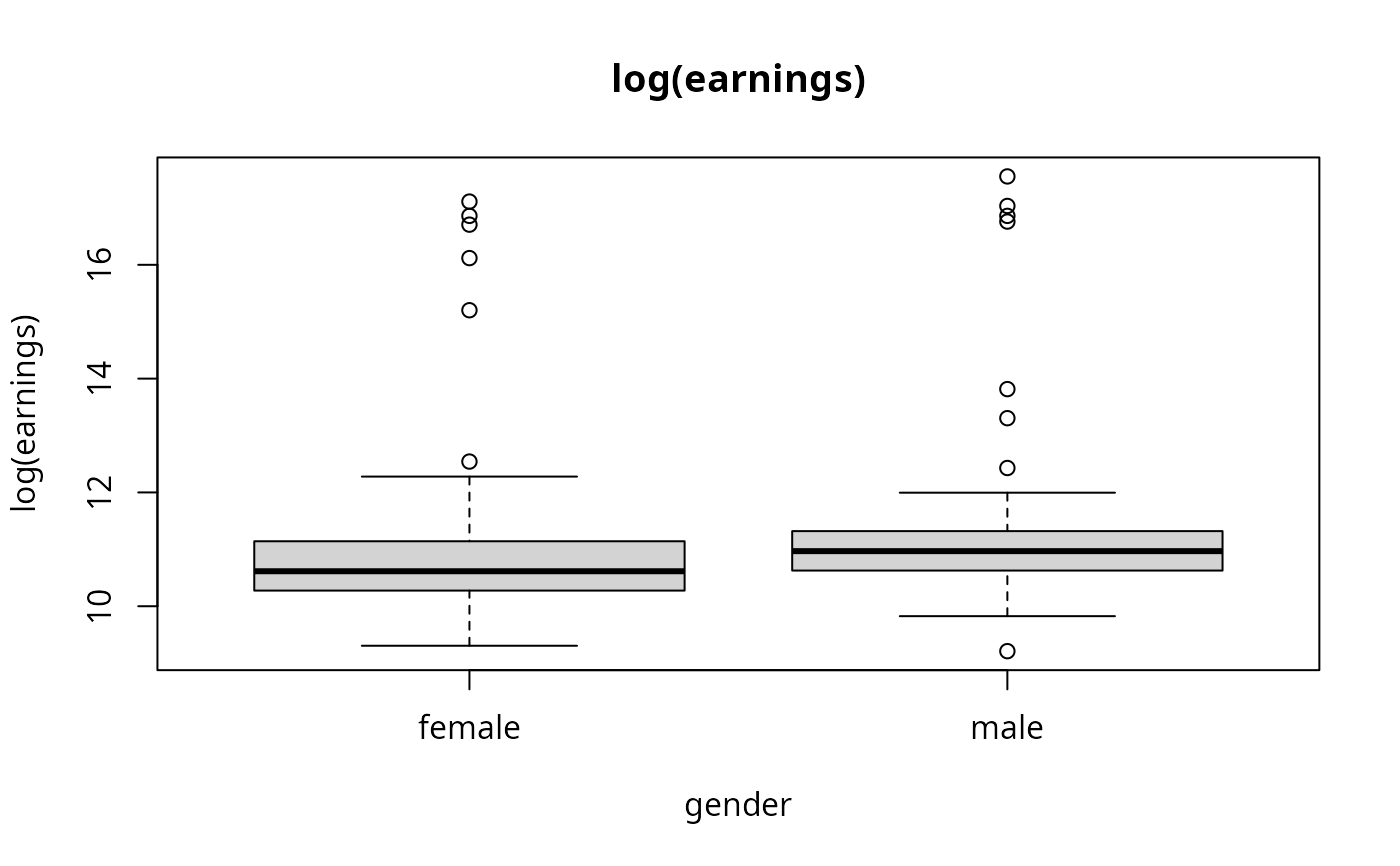
 plot(log(earnings) ~ gender, main = "log(earnings)")
plot(log(earnings) ~ gender, main = "log(earnings)")
 ## celebrity vs. non-celebrity earnings
noncel <- subset(Parade2005, celebrity == "no")
cel <- subset(Parade2005, celebrity == "yes")
library("ineq")
plot(Lc(noncel$earnings), main = "log(earnings)")
lines(Lc(cel$earnings), lty = 2)
lines(Lc(earnings), lty = 3)
## celebrity vs. non-celebrity earnings
noncel <- subset(Parade2005, celebrity == "no")
cel <- subset(Parade2005, celebrity == "yes")
library("ineq")
plot(Lc(noncel$earnings), main = "log(earnings)")
lines(Lc(cel$earnings), lty = 2)
lines(Lc(earnings), lty = 3)
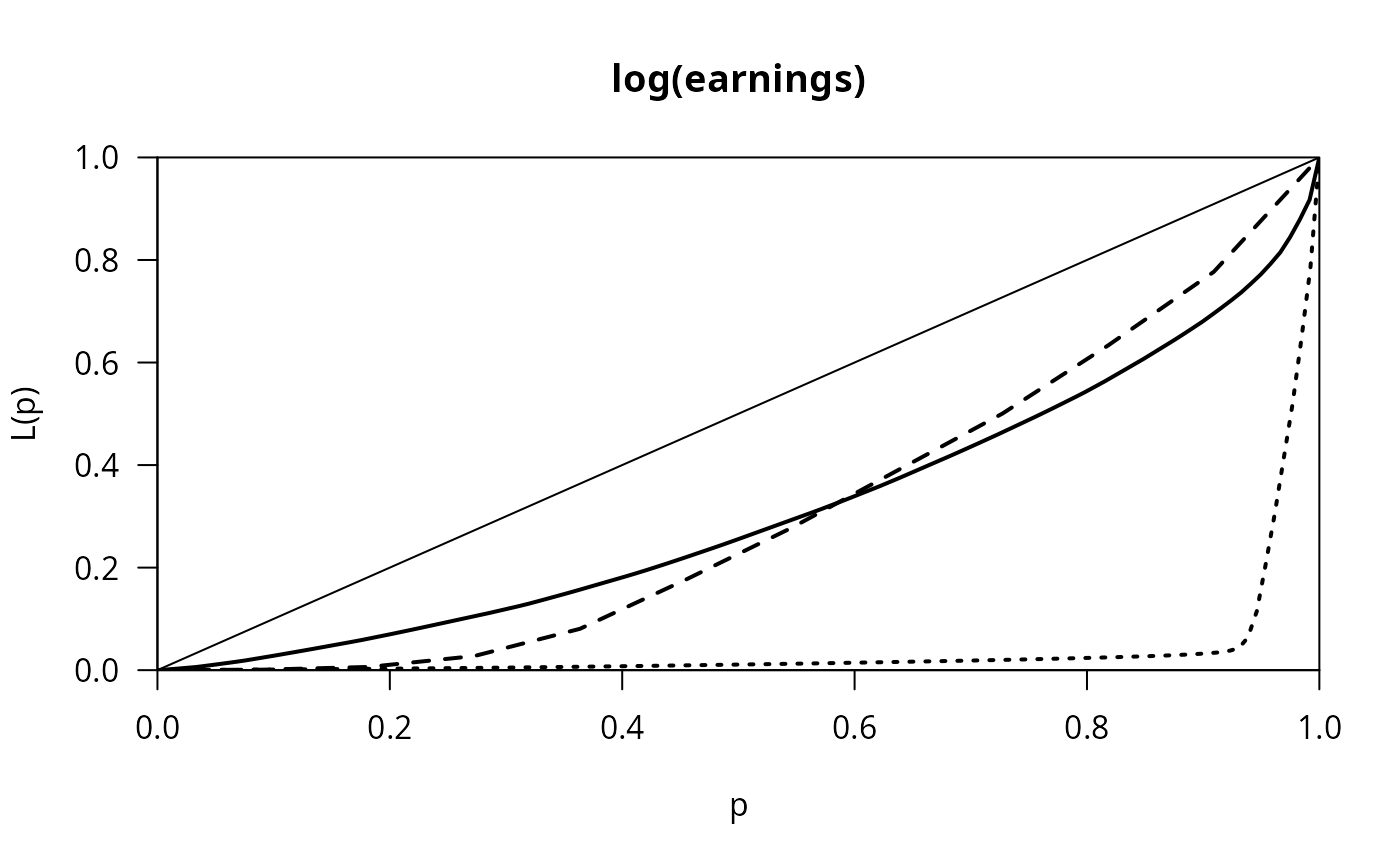 Gini(noncel$earnings)
#> [1] 0.3814012
Gini(cel$earnings)
#> [1] 0.38754
Gini(earnings)
#> [1] 0.9228179
## detach data
detach(Parade2005)
Gini(noncel$earnings)
#> [1] 0.3814012
Gini(cel$earnings)
#> [1] 0.38754
Gini(earnings)
#> [1] 0.9228179
## detach data
detach(Parade2005)